8.2 Unsupervised learning
Unsupervised learning tries to discover interesting structure in data with no labels, this is also called knowledge discovery. Unsupervised learning is arguably more typical of human and animal learning.
When we’re learning to see, nobody’s telling us what the right answers are — we just look. Every so often, your mother says ‘that’s a dog,’ but that’s very little information. You’d be lucky if you got a few bits of information—even one bit per second—that way. The brain’s visual system requires \(10^{14}\) [neural] connections. And you only live for \(10^9\) seconds. So it’s no use learning one bit per second. You need more like \(10^5\) bits per second. And there’s only one place you can get that much information—from the input itself.
- Geoffrey Hinton, ML professor at University of Toronto
Unsupervised learning wants to find structure in data, which data belongs to which category, in a mathematically way that is
8.2.1 Discovering clusters
In the image below a dendrogram of the hierarchical cluster on the left hand side is derived of the correlation matrix on the right hand side.
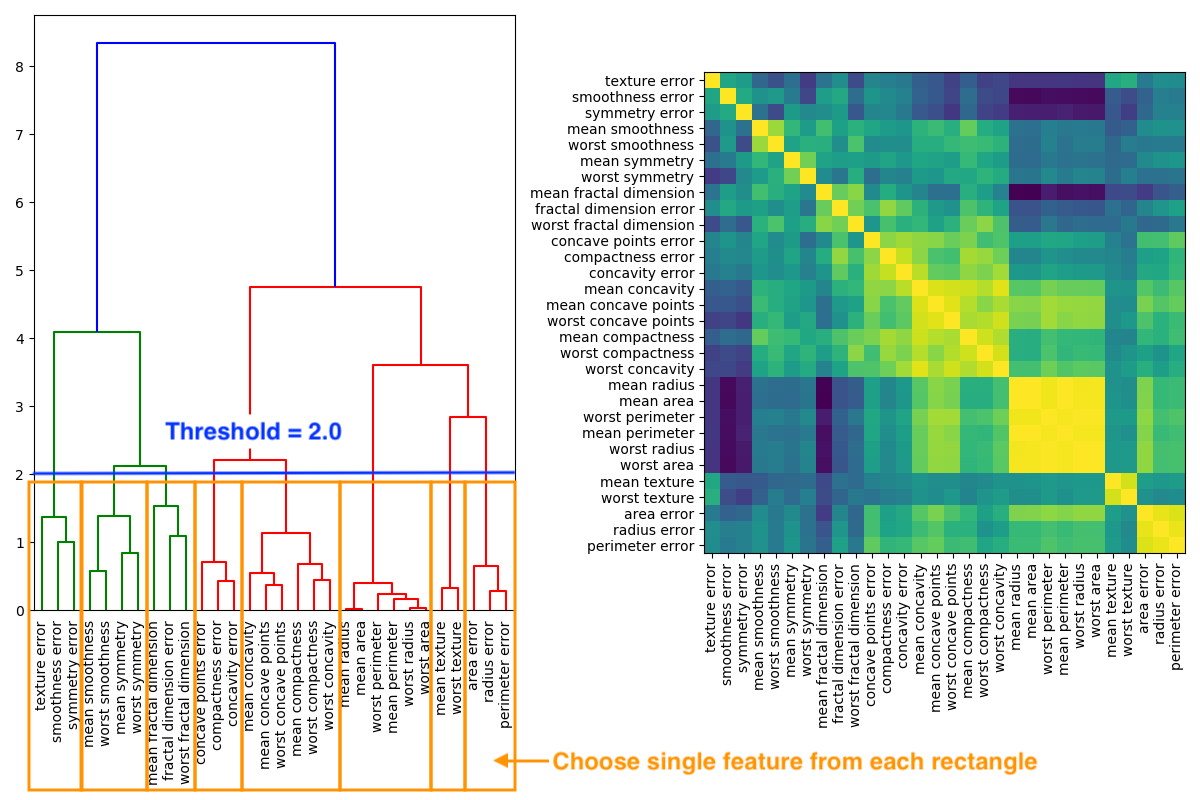
Real world examples:
- New type of stars were discovered by Cheeseman at al with the autoclass system (Cheeseman et al. 1988).
- Grouping customers in e-commerce into clusters based on purchasing or web-surfing behavior (Berkhin 2006).
8.2.2 Discovering latent factors
If data is high dimensional it is often useful to reduce dimensionality. If data appear to be high dimensional there may be s small number of degrees of variability, those are called latent 21 factors.
Those latent factors can be found with methods such as principle component analysis (PCA), t-SNE, autoencoders.
Latent factors:
- Latent factors are low dimensional representation of data
- given: height, weight, age, body temperature, EKG measurement
- latent factor \(\implies\) healthy
- Algorithms to discover latent factors
- principle component analysis (PCA)
- t-SNE
- autoencoders
- see chapter 7.4.2.3 for details of the algorithms
References
german: verborgen↩︎