4.1 Topics in data ethics
Data ethics is a wide field with many aspects, this section is meant to be an introduction into the field and therefore focuses on a few topics which are of high relevance.Topics in data ethics:
- Need for recourse and accountability
- without accountability systems will not be accepted
- mechanisms have to be in place to solve issues
- Feedback loops
- lead to information bubbles and spread of conspiracy theories
- avoided by careful design of metrics
- monitore results
- Bias
- leads to discrimination and racism
- there are no un-biased data
- audit
- data
- results
4.1.1 Recourse and accountabilty
There are already plenty of examples were machine learning algorithms had negative impacts on peoples life due to wrong or biased data.
One example is a large-scale study of credit reports by the Federal Trace Commission (FTC) in 2012. The study reports that 26% of consumers had at least one mistake, 5% had errors that could be devastating. For cases like that, mechanisms must be in place to fix those problems if they occur, and steps in the development process have to implemented to avoid such problems in the first place. This can be done by data and code audits.
4.1.2 Feedback loops
Machine learning algorithms will optimize the metric given to it. This can lead to edge cases, for example in recommendation systems, which create information bubbles and spread of conspiracy theories. To avoid such unwanted effects careful design of the metrics and monitoring of the results are necessary.
Also a way to allow users to give feedback to the system can help to identify unwanted feedback loops.
The coverage of the Mueller report by Russia Today has a very high number of channels recommending the video, it is not clear how this high number is achieved, but assumption is that Russia Today has successful way to take advantage of YouTube’s recommendation system.
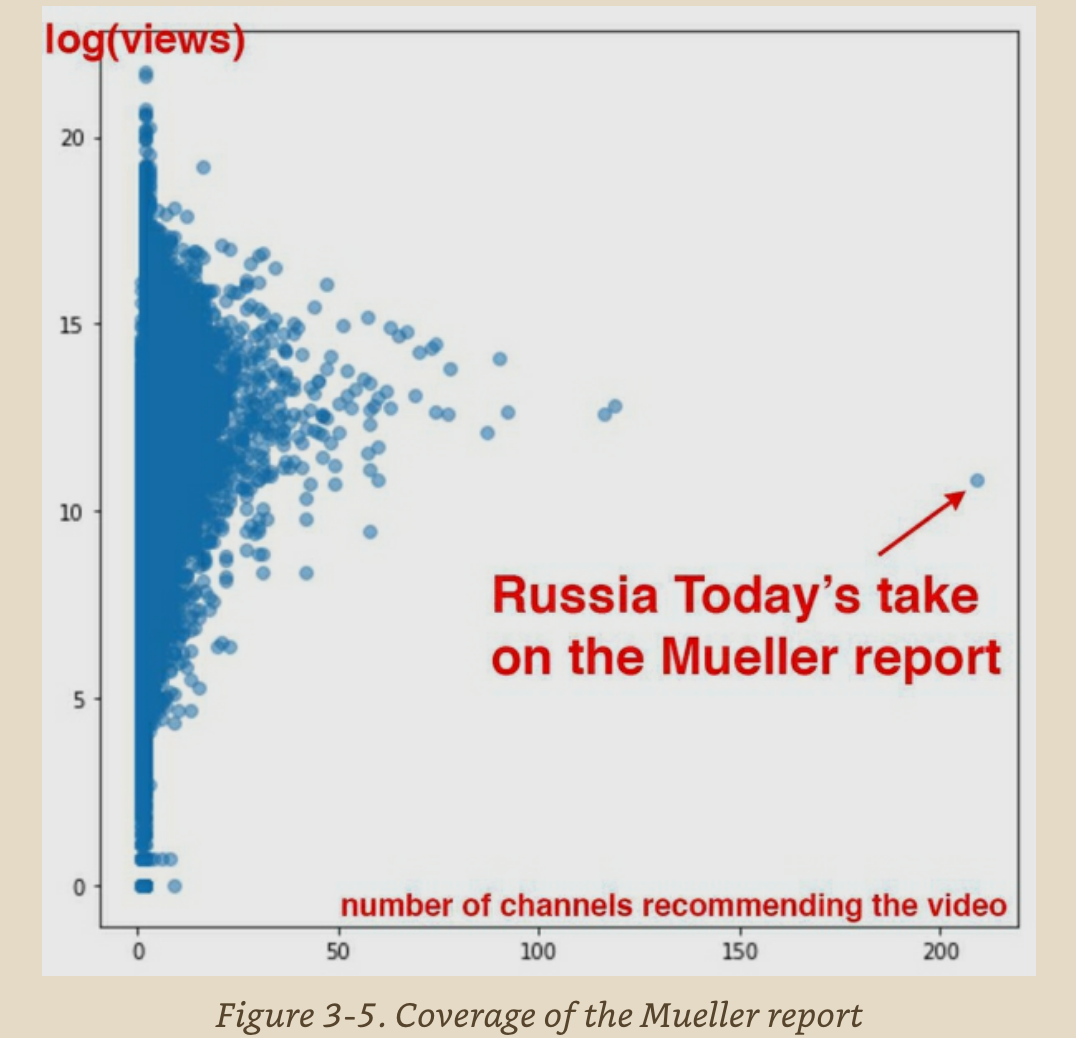
Mueller report recommendation of YouTube, figure from (Jeremy Howard 2020)
4.1.3 Bias
Bias leads to predictions of the machine learning algorithm which are flawed by data which are misrepresenting reality or represent social bias. For example the COMPASS algorithm used for sentencing and bail decisions in the US, when tested by ProPublica
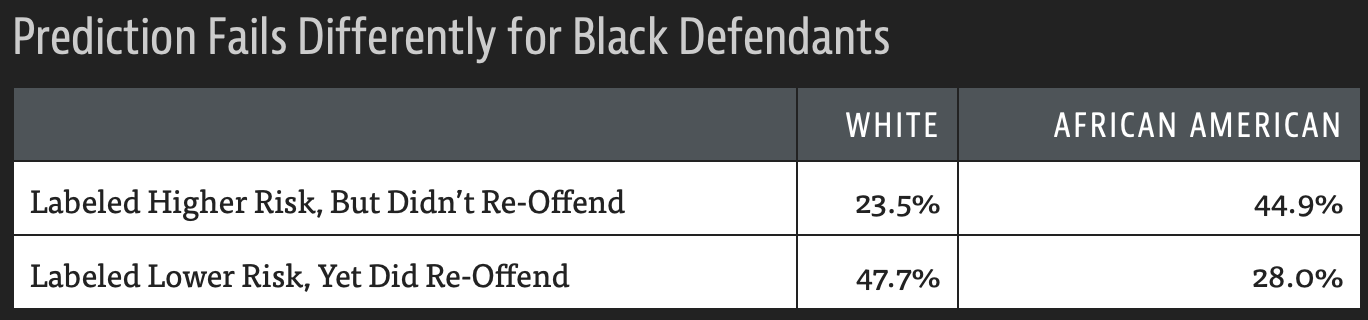
Results from COMPASS algorithm, figure from https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
The numbers show that more African American who were rated higher risk did not re-offend, but lower risk White people did re-offend more often than African Amercian.
Google Photos autocategorized photos show racial bias in computer vision

Racist bias of Google Photo, figure from (Jeremy Howard 2020)
Part of the problem is the source of data which is heavily western based as shown in the paper “No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World” (Shankar et al. 2017).
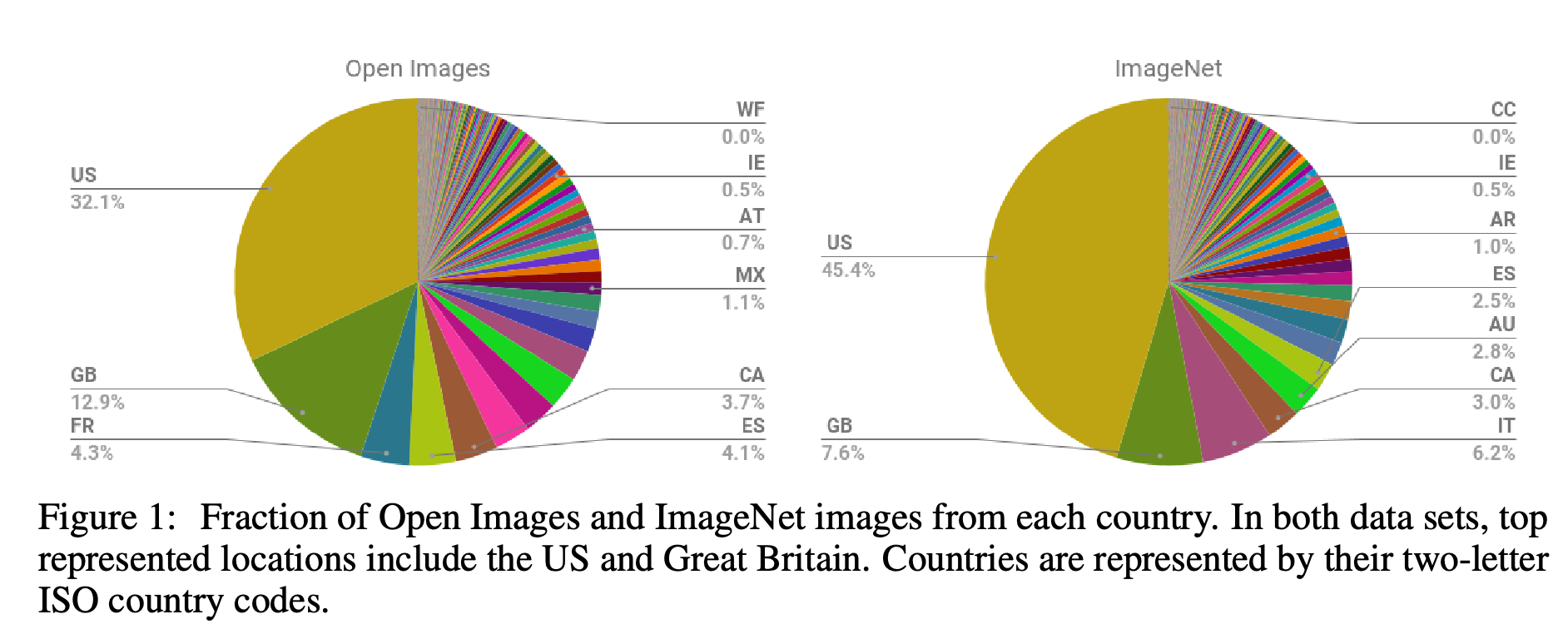
ImageNet and Open Images data origin, figure from (Shankar et al. 2017)
This reflects in the ability of algorithms to classify pictures across different nations In the next graph it is shown that a classifier trained on Open Image data does not work to the same accuracy for images from Ethiopia and Pakistan as it does for images form the US and Australia.

Classifier trained on Open Images failing across different nations, figure from (Shankar et al. 2017)